In a large production cluster, hardware failures are inevitable. Hard drives fail, network switches disconnect, and servers crash. To ensure your streaming data remains available despite these issues, Kafka implements a robust partition-level **Replication Model**.
Replication ensures that multiple copies of your data exist across different brokers. If a server hosting your data crashes, Kafka instantly switches to another copy with zero downtime. Let's look at how this works.
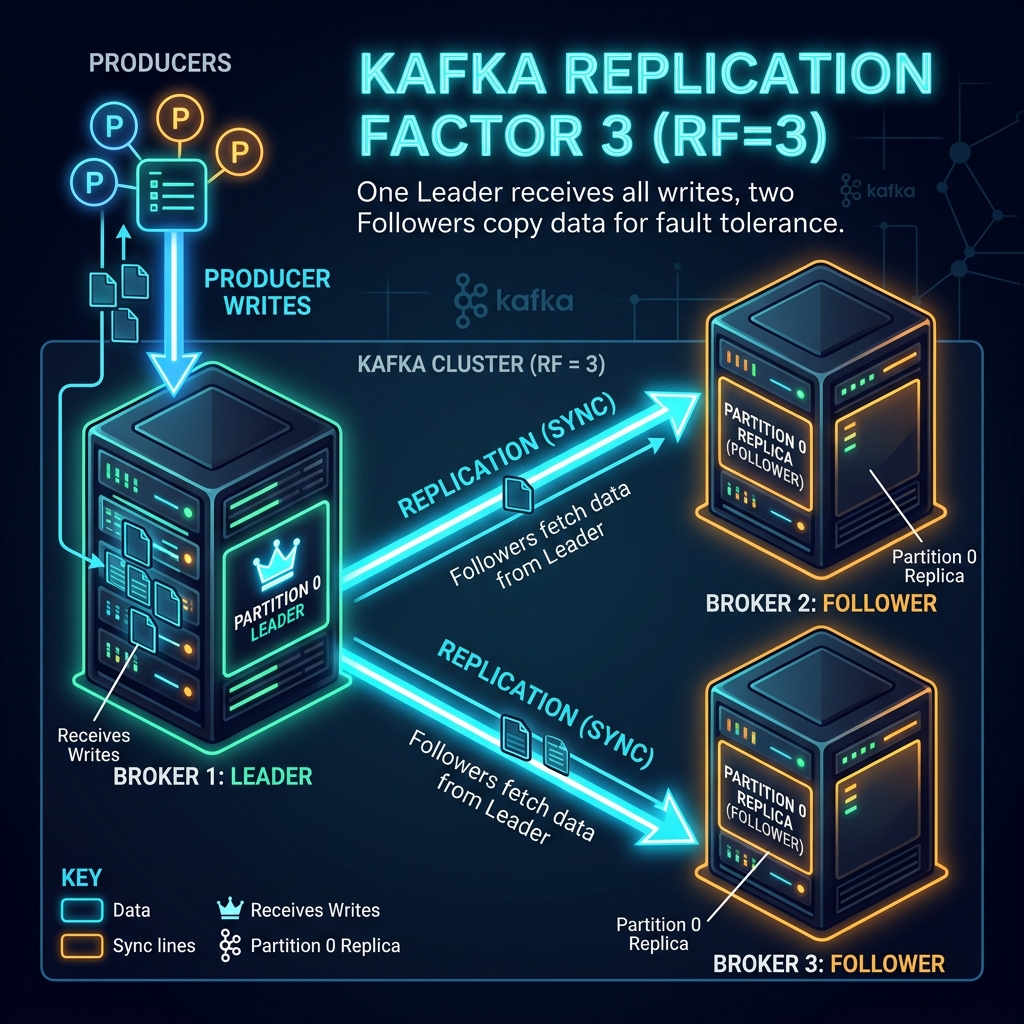
Imagine a live musical performance:
- The Leader is the Lead Singer. They stand at the front microphone, handle all interactions with the audience (Producers and Consumers), and lead the song.
- The Followers are the Backup Singers. They stand behind the leader, listen to what the leader sings, and copy it in real-time. If the lead singer suddenly loses their voice (broker failure), the stage manager instantly promotes one of the backup singers who is in sync to the lead microphone (Leader Election). The concert continues without interruption.
Replication Roles: Leader vs. Follower
For every partition in your Kafka topics, brokers are assigned specific roles:
- The Leader: Each partition has exactly one broker designated as the leader. The leader is responsible for handling all incoming writes from producers and reads from consumers.
- The Followers: The remaining brokers configured by the replication factor act as followers. They do not serve client requests; instead, they periodically poll the leader to copy new log records to their local disks.
What are In-Sync Replicas (ISR)?
An **In-Sync Replica (ISR)** is any follower broker that is successfully keeping up with the leader. If a follower crashes or experiences network lag, it falls behind. If it doesn't catch up within 30 seconds (configured by replica.lag.time.max.ms), Kafka removes it from the ISR pool.
This is crucial: **Kafka will only elect a new leader from the active ISR pool** to guarantee that the new leader has all previously confirmed messages.
Topic Creation with Replication Factor
When you create a topic, you define the Replication Factor. For production systems, a factor of **3** is the standard recommendation:
// Create a topic "payments" with 6 partitions and a replication factor of 3
NewTopic paymentsTopic = new NewTopic("payments", 6, (short) 3);
adminClient.createTopics(Collections.singletonList(paymentsTopic)).all().get();Unclean Leader Elections
What happens if all brokers in the ISR pool crash, and only an out-of-sync broker remains online? You must make a choice via unclean.leader.election.enable:
- Set to false (Default since 0.11): The partition remains offline and unavailable until the original leader recovers. This prevents data corruption/loss but sacrifices availability.
- Set to true: Kafka allows the out-of-sync broker to become the leader. The partition goes online instantly, but you lose any messages that were not synced, causing log truncation.
Conclusion
Kafka replication balances availability and durability. By splitting broker tasks into leaders and followers, maintaining a strict ISR registry, and automating leader election, Kafka recovers from server outages in milliseconds with zero data loss.