When you call producer.send(record) in a Java application, you might assume the message is sent directly over the network to a broker immediately. Under the hood, however, Kafka utilizes a highly optimized, asynchronous batching pipeline to maximize throughput and network efficiency.
Understanding this internal pipeline is key to tuning your producers for performance and reliability. Let's trace the journey of a message inside the Kafka producer client from code to broker.
Imagine a warehouse shipping department:
- Serializer: Converts loose products into uniform, catalog-coded boxes.
- Partitioner: Reads the customer address and writes which delivery truck it needs to load onto.
- Record Accumulator: Grouping items by truck route on pallets. Instead of driving a delivery truck out for every single envelope, workers wait until a pallet is full (
batch.size) or a timer expires (linger.ms) before loading it onto the truck. - Sender Thread: The driver who takes the loaded pallets and drives them to the central shipping center.
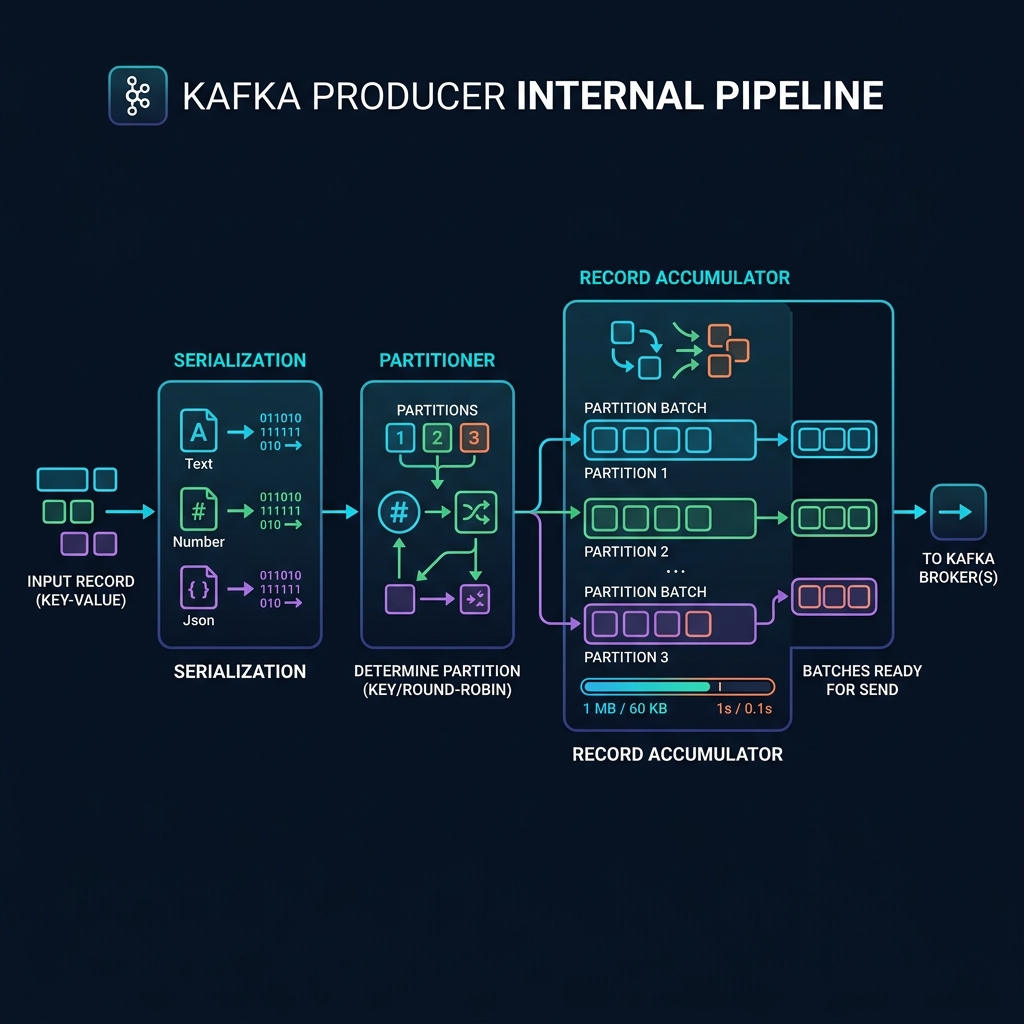
Step-by-Step Internal Flow
The producer client performs several actions in sequence before network transmission begins:
1. Serialization
Computers cannot transmit raw Java objects over network cables. The producer first passes your key and value through a **Serializer** (such as StringSerializer or KafkaAvroSerializer) to convert them into raw byte arrays.
2. Partitioning
The serialized bytes pass to the **Partitioner**. If you specified a partition, it uses it. If not, it hashes the message key to select a partition, or runs a sticky round-robin pass to distribute messages across partitions.
3. The Record Accumulator (Batching Buffer)
Instead of sending the message immediately, the producer stores the record in a memory buffer called the Record Accumulator. This accumulator has memory queues grouped by topic-partition. Messages are packed into batches (sized by batch.size, default 16KB).
Two main parameters control when these batches are released:
- batch.size: Maximum memory size of a single batch. Once filled, it's sent immediately.
- linger.ms: Maximum time to wait for a batch to fill. If set to 5ms, the producer waits up to 5ms for more messages to arrive before sending the batch, boosting throughput at the cost of tiny latencies.
4. The Sender Thread
A dedicated background thread runs continuously. It polls the Record Accumulator, converts completed batches into socket channel requests, and sends them to the appropriate Kafka broker leaders.
Basic Java Producer Example
Here is a configured example showing these batching variables:
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// Tuning for high throughput:
props.put("batch.size", 65536); // Increase batch limit to 64KB
props.put("linger.ms", 20); // Wait up to 20ms for batching
props.put("compression.type", "lz4"); // Compress batches using fast LZ4 algorithm
Producer producer = new KafkaProducer<>(props);
ProducerRecord record = new ProducerRecord<>("orders", "key1", "Order details here");
// Send asynchronously with a callback listener
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception e) {
if (e != null) {
e.printStackTrace();
} else {
System.out.println("Sent successfully to partition: " + metadata.partition());
}
}
});
producer.close(); // Flushes remaining batches and releases memory Conclusion
Kafka producers are designed to be asynchronous and high-performance. By grouping records into batches in memory using the Record Accumulator, they minimize network overhead. Tuning batch.size and linger.ms allows you to control the sweet spot between latency and throughput.